I’m somewhat disconcerted by this recent article that appeared in USA Today. I wouldn’t have noticed it, except for the fact that it was critiqued to some extent by Mark Chu-Carroll and various commenters over at Good Math, Bad Math. I might be somewhat happier if I hadn’t noticed it.
The proposal to impose a 50 point minimum grade for an assignment (on a 100 point scale) is problematic for a number of reasons. Some of these are practical, and can be seen clearly by considering some analogous scenarios. I’m fairly certain that it would be in some people’s interest to impose similar artificial bounds in other situations, but such a proposition would be a complete non-starter. Declaring an NHL player’s plus-minus rating to have a minimum value of 4 would clearly invalidate the descriptive value of the statistic. Declaring that employees can be given no worse than a “satisfactory” review would have interesting repercussions in the corporate environment, since it would effectively eliminate the ability to fire someone for non-performance of their job, or even incompetence.
Apparently, however, mathematical competence is not required in this arena. According to the article, the argument in favor of this artificial minimum is this:
Other letter grades — A, B, C and D — are broken down in increments of 10 from 60 to 100, but there is a 59-point spread between D and F, a gap that can often make it mathematically impossible for some failing students to ever catch up.
“It’s a classic mathematical dilemma: that the students have a six times greater chance of getting an F,” says Douglas Reeves, founder of The Leadership and Learning Center, a Colorado-based educational think tank who has written on the topic.
Last time I checked, the closed interval ![S := \left[0,100\right]](https://s0.wp.com/latex.php?latex=S+%3A%3D+%5Cleft%5B0%2C100%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) in the integers contains 101 elements, and a standard 90-80-70-60 scale allocates them in such a way that there is a 60 point spread between the minimum scores meriting an F and a D. Feel free to check my arithmetic, but even a hand calculator can usually get
in the integers contains 101 elements, and a standard 90-80-70-60 scale allocates them in such a way that there is a 60 point spread between the minimum scores meriting an F and a D. Feel free to check my arithmetic, but even a hand calculator can usually get  correct. Apparently correct arithmetic is not important in an argument supporting how grades should be computed.
correct. Apparently correct arithmetic is not important in an argument supporting how grades should be computed.
I’m also astounded—perhaps I shouldn’t be, but I am—that the head of a think tank would propose that statement as a “classic mathematical dilemma”. It certainly appears to contain two classic mathematical errors, however: one being a fencepost error, and the other being an unsupported assumption that grades are uniformly distributed over  . If the grades obtained by students were distributed uniformly over , then the expected value of student grades would be 50. So far as I am aware, neither high school graduation rates nor university retention and graduation rates support such a claim. Moreover, we should expect strictly more values corresponding to an A than to any of the grades B, C, or D on a given assignment or exam, since it contains one more element of than the others do. Would anyone care to provide the empirical evidence justifying such a result?
. If the grades obtained by students were distributed uniformly over , then the expected value of student grades would be 50. So far as I am aware, neither high school graduation rates nor university retention and graduation rates support such a claim. Moreover, we should expect strictly more values corresponding to an A than to any of the grades B, C, or D on a given assignment or exam, since it contains one more element of than the others do. Would anyone care to provide the empirical evidence justifying such a result?
As unsettling as these errors are, I find the sidebar to be more disquieting. The examples it provides for calculating grades do not correspond to the general assumption in the article that a letter grade of F is recorded, and then considered to be 0 at some later point. Rather, it shows what happens when we have recorded the scores on a 100-point scale, and then compute the mean with the actual score or with a false minimum of 50. In these comparisons, the recorded failing grade is not in general a zero.
Let’s take a slightly closer look at what is happening here. There are two grading scales in use here: the closed interval ![S=\left[0,100\right]](https://s0.wp.com/latex.php?latex=S%3D%5Cleft%5B0%2C100%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) of integer scores, and the set
of integer scores, and the set  of letter grades. The 90-80-70-60 convention establishes a surjective mapping
of letter grades. The 90-80-70-60 convention establishes a surjective mapping 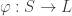 that preserves the standard order on each of these sets. However,
that preserves the standard order on each of these sets. However, 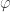 is not injective, so we cannot define a consistent arithmetic on
is not injective, so we cannot define a consistent arithmetic on  in terms of
in terms of  . The argument provided in support of this 50-minimum grading scale is, in effect, an argument about how a representative of the preimage
. The argument provided in support of this 50-minimum grading scale is, in effect, an argument about how a representative of the preimage 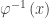 should be selected for each
should be selected for each 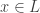 .
.
Unfortunately, this argument does not go through if we already have scores recorded. We are not free to select any element of the preimage. At least in the sciences, there’s a term for such an operation: it’s called falsification of data. Viewed this way, the implications of the grading policies being adopted by some school districts are, at best, disturbing.
Copyright © 2008 Michael L. McCliment.





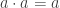

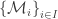





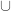
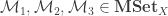


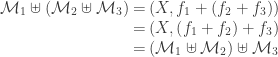
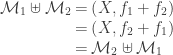
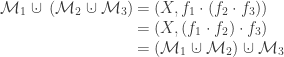

be partially ordered sets. Then
and
whenever the suprema and infima exist.




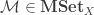

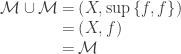
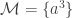
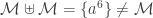




 Posted by Michael McCliment
Posted by Michael McCliment  is a family of multisets over
is a family of multisets over 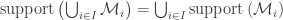 .
. for all
for all  .
. provided that all of the multisets
provided that all of the multisets 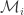 have the same support.
have the same support.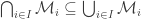 .
.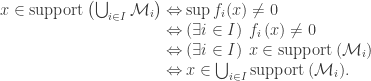
 for all
for all  and
and 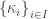 is given by
is given by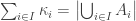
 are disjoint and
are disjoint and  for all
for all 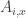 be a family of disjoint sets such that
be a family of disjoint sets such that 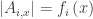 , we have
, we have
 is an upper bound for
is an upper bound for  in the linearly ordered set
in the linearly ordered set  , and so
, and so 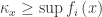 . The result in part (iii) follows immediately since this holds for all
. The result in part (iii) follows immediately since this holds for all 
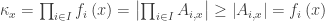
 for all
for all 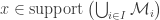 , which is the common support of all multisets in the family
, which is the common support of all multisets in the family 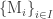 . If
. If  is not in this support, then
is not in this support, then  . In either case,
. In either case,  and
and 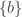 .
.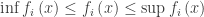
 -friendly. With some of the themes available here, the
-friendly. With some of the themes available here, the  can, as we’ve already seen, be represented in terms of the characteristic function as
can, as we’ve already seen, be represented in terms of the characteristic function as
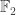 (just as we took the minimum in this field when looking at the intersection). This maximum is, in fact, a
(just as we took the minimum in this field when looking at the intersection). This maximum is, in fact, a 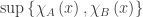 for each
for each  , we let
, we let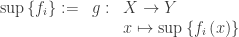
 where each
where each 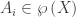 , we have
, we have .
. because both codomains—
because both codomains—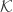 of cardinals has an ordinal supremum
of cardinals has an ordinal supremum  . The cardinal
. The cardinal  which is equinumerous with
which is equinumerous with 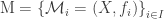 be a family of multisets over a set
be a family of multisets over a set  is the set
is the set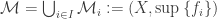 .
. are defined on a common domain, and every set of cardinals has a supremum. This ensures that the multiset union is well-defined on
are defined on a common domain, and every set of cardinals has a supremum. This ensures that the multiset union is well-defined on 